iStockphoto /盖蒂图片社
Nvidia最终确定GPUDirect Storage 1.0以加速AI、HPC
Nvidia GPUDirect Storage的驱动程序达到1.0状态,可在GPU和存储之间直接访问内存,并提高数据密集型AI、HPC和分析工作负载的性能。

英伟达于2019年底推出的Magnum IO GPUDirect Storage软件,在经过一年多的测试后,最终达到1.0状态。该软件旨在加速人工智能、分析和高性能计算的工作负载。
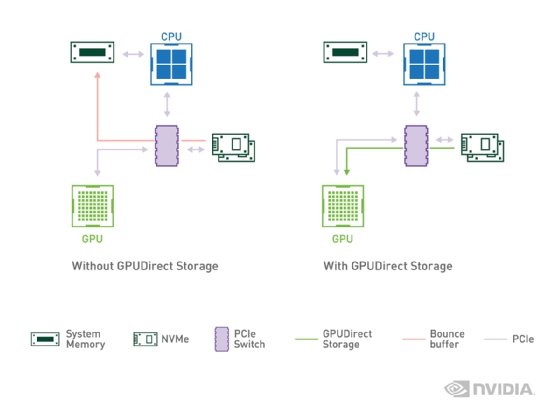
Magnum IO GPUDirect存储驱动程序使用户能够绕过服务器CPU,在高性能处理器之间直接传输数据GPU内存和存储,通过作为PCIe使用要求最苛刻的数据密集型应用程序,切换以降低I/O延迟并提高吞吐量。
英伟达加速计算技术产品营销经理Dion Harris表示,GPUDirect存储降低了CPU利用率并使cpu能够专注于它们为运行处理密集型应用程序而构建的工作。
在本周的ISC高性能2021数字会议上,Nvidia宣布增加了万能IO GPUDirect其HGX AI超级计算平台的存储软件,以及新的A100 80 GB PCIe GPU和NDR 400G InfiniBand网络。Nvidia必须与企业网络和存储提供商合作,以实现GPUDirect存储。
存储厂商支持GPUDirect
具有集成GPUDirect存储的通用产品的存储供应商包括数据直接网络、海量数据和WekaIO。其他正在开发的产品包括戴尔技术公司、Excelero、惠普企业、日立万达、IBM、美光、NetApp、,馆的数据系统和ScaleFlux。
资深技术分析师史蒂夫•麦克道尔沼泽的见解和策略,说英伟达的GPUDirect存储软件通常会使用高性能存储阵列能够提供所需的吞吐量gpu和支持高性能远程直接内存访问(RDMA) InfiniBand等互连。GPUDirect存储配对的例子包括IBM弹性存储系统(ESS) 3200他说,这两款产品分别是NetApp的EF600全闪存NVMe阵列和Dell EMC的PowerScale scale scale NAS系统。
GPUDirect Storage是为生产级和重型研究深度学习环境而设计的。 史蒂夫·麦克道尔Moor Insights&Strategy高级技术分析师
“GPUDirect Storage是为生产级和繁重的研究而设计的深度学习环境McDowell说,他指出,该技术的目标是在I/O成为瓶颈的情况下,安装大量致力于训练算法的gpu。
Nvidia DGX SuperPod与IBM ESS 3200
IBM本周宣布,它已经更新了两节点、四节点和八节点的Nvidia DGX Pod配置的存储参考架构,并承诺支持DGX叠加到第三季度末,它的ESS 3200。SuperPad从20个Nvidia DGX A100系统开始,可以扩展到140个系统。
IBM产品组合GTM和联盟的项目总监Douglas O'Flaherty表示,在两节点Nvidia DGX A100上使用GPUDirect存储可以使数据吞吐量几乎翻一番,从每秒40 GB增加到77 GB,只运行一台IBM ESS 3200光谱尺度.
O'Flaherty说:“它向Nvidia展示的是一个GPU可以开始处理多少数据。它向我们展示的是,当您的开发人员和应用程序接受这一点时,特别是在这些大型数据环境中,您确实需要确保您没有将瓶颈转移到存储上。”。“使用我们最新版本的ESS 3200,我们只使用了很少的几个系统就实现了巨大的吞吐量。”
O'Flaherty说,对Nvidia GPUDirect Storage最感兴趣的客户包括从事自动驾驶汽车的汽车制造商、自然语言处理工作量大的电信提供商、寻求减少延迟的金融服务公司以及拥有大型复杂数据集的基因组学公司。
据公司首席营销官兼联合创始人杰夫·登沃斯称,初创公司Vast Data已经收到了一些GPUDirect存储系统的大订单。例如,媒体工作室进行容量数据捕捉以创建3D视频,金融服务公司运行阿帕奇火花的分析引擎急流开放的GPU数据科学框架,和HPC中心和制造商使用PyTorch机器学习库。
Denworth声称,在Rapids和PyTorch项目中使用GPUDirect Storage已经使Vast Data能够以比传统NAS系统快80倍的速度为标准Spark或Postgres数据库提供数据。
登沃斯说:“我们为这项新技术所参与的项目数量感到惊喜。”“这真的不是简单地让某些人工智能应用程序运行得更快的问题。有一个完整的范围面向GPU的工作负载客户现在开始倾向于这种gpu直接存储模式,以满足这些极度饥饿的机器的需求。”
Carol Sliwa是TechTarget的资深撰稿人,主要研究存储阵列和驱动器、闪存和内存技术以及企业架构。