存储

iStockphoto /盖蒂图片社
用于数据分析的机器学习可以解决大数据存储问题
在Lambda架构、fpga和容器等主要供应商和技术的支持下,探索人工智能和机器学习如何解决大数据分析挑战。

各行各业的大公司已经在现有数据中发现了隐藏的业务价值,使用机器学习算法在数据中发现隐藏的洞察力很快就成为了常态。尽管它有这么多好处,但机器学习用于数据分析带来了一些挑战,特别是在涉及存储基础设施时。
因为数据可能包含隐藏的价值,组织可能是不太倾向于清除老化数据.这导致存储被加速消耗,使容量规划工作复杂化。而且,实际的分析过程会在底层存储基础设施上产生额外的负载。
有些讽刺的是,一些供应商已经开始使用人工智能作为工具来解决由大数据分析.就目前的情况来看,他们的机器学习分析工作并不是基于单一的技术,而是基于不同的技术集合。
λ架构
在使用人工智能进行工作负载分析和容量规划时,访问相关的当前数据是很重要的存储使用和运行状况.即便如此,完全依赖实时数据可能并不总是可取的。
的问题使用实时流数据数据是原始的,完全未经整理。数据流中可能存在缺陷,而实时使用数据的事实极大地限制了可以完成的处理量。
使用相对最新的(但不是实时的)数据,通常可以通过用于数据分析的机器学习产生更多信息。但这些数据并不像流媒体上的数据那样是最新的现在.
的λ架构解决这个问题的同时流数据到两个不同的层:批处理层和速度层。批处理层的工作只是存储数据。因为这些数据不是实时操作的,所以可以使用批处理规则来提高数据的质量。在某些模型中,批处理层还可以向第三层(服务层)提供数据,该层创建批处理视图以响应查询请求。
入站数据还会流进速度层,该层提供实时数据视图。
当对Lambda架构进行查询时,组织通过合并来自批处理视图和实时—速度—视图的分析获得结果。这使得Lambda体系结构能够提供比其他方法更全面和完整的数据图。
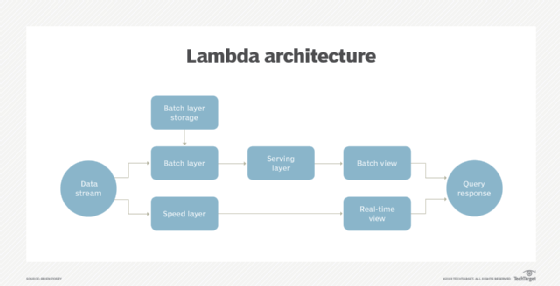
要让Lambda体系结构工作,它必须具有非常低的延迟,并且具有足够的可伸缩性,以容纳入站数据流。因此,Lambda架构被设计为扩展到多个节点例如,超融合。这种扩展架构还允许系统对硬件故障具有容错能力。
定制的fpga
自定义现场可编程门阵列(fpga)在IT领域相对较新,但已在电气工程中使用多年。尽管如此,硬件供应商开始使用fpga作为cpu和gpu的替代品,用于数据分析的机器学习。事实上,英特尔在2015年花了167亿美元收购了FPGA制造商Altera。
fpga历来被用于降低电子设备设计的成本和复杂性。现代电子设备几乎总是基于集成电路(ICs)的使用。这意味着电子工程师设计一个新设备要么需要定位满足设备需求的集成电路,要么需要定制集成电路,这是一个昂贵而复杂的过程。
在电子工程中,fpga消除了生产定制集成电路的需要。与其他类型的集成电路不同,FPGA是可编程的。这意味着电子工程师可以将FPGA配置为就像一个定制的集成电路.
不仅仅是FPGA作为定制IC的能力让它成为机器学习的理想选择。fpga还有另外两个必须考虑的特性:
- 它们可以实现极低的延迟。这在很大程度上归因于FPGA能够充当定制的、专门构建的设备,而不是像CPU那样充当通用设备。此外,fpga不需要运行Windows或Linux等通用操作系统。由于fpga可以实现如此低的延迟(有时低至一微秒),因此它很适合用于人工智能机器学习平台。
- 它们可以执行浮点运算。虽然fpga可以执行浮点运算,但它们缺乏现代CPU或GPU的速度和精度,这使得当前一代fpga不是用于人工智能训练的好选择。然而,他们擅长推理任务。这意味着存储供应商可以使用fpga作为平台将机器学习能力集成到存储硬件中只要最初的训练数据是在不同的平台上创建的,然后复制到设备上。
培训与推理
在高水平上,机器学习是基于训练和推理的概念。训练就是听起来的那样。它是教机器学习平台如何执行特定任务的过程。
训练过程的一个经典例子是2012年的一个实验,在这个实验中,一台计算机算法被训练去识别猫。这个实验强调了训练过程的CPU和数据密集型特性。学习识别一只猫需要16000台电脑来分析1000万张猫的图像。其结果是一种算法,可以识别出一张图像是猫还是不是猫。
机器学习的另一个主要组成部分是推理,这是指机器学习算法在训练过程完成后执行的任务。例如,在前面提到的猫识别算法中,当算法查看之前未见过的图像,并根据它过去的训练正确判断图像是否包含猫时,就会进行推理。
在计算上,推理与训练是截然不同的。虽然训练过程是非常密集的cpu,通常需要分析大量的数据,但推理仅仅基于训练过程中积累的知识。因此,它发生得比训练快得多,花费的精力也少得多。
集装箱存储
尽管容器最著名的用途是运行业务应用程序的平台,但容器对于机器学习也是可行的。
训练机器学习算法的过程往往是计算密集型的。然而,一旦经过培训,企业通常可以使用这些算法,而不需要大量的CPU资源。由于机器学习过程往往是相对轻量级的,它们正日益增多在容器内运行.最常被容器化的机器学习技术的一个例子是TensorFlow。
TensorFlow是谷歌的一个开源Python库,旨在使机器学习更容易。谷歌创建了自己的定制IC张量处理单元,为使用张量而设计。然而,谷歌设计的TensorFlow可以在几乎任何平台上工作,包括容器。
容器化TensorFlow的一个最引人注目的原因是它的应用程序可以大规模运行。组织可以跨TensorFlow集群分布计算图,并可以将组成这些集群的服务器容器化。
供应商支持
Dell EMC PowerMax系列是首批将机器学习纳入数据分析功能的存储产品之一。戴尔EMC广告PowerMax作为世界上最快的存储阵列,它支持高达1000万IOPS,允许150 GBps的带宽。
PowerMax阵列令人印象深刻的性能,至少部分归功于机器学习。集成的机器学习引擎自动使用预测分析,根据对数据的预期需求,将数据放置到最佳的媒体类型(闪存或存储类内存),从而实现性能最大化。
希望利用机器学习能力进行存储的组织应该从决定他们希望获得什么开始。
Dell EMC并不是唯一一家使用机器学习使存储更智能化的供应商。惠普公司(Hewlett Packard Enterprise)使用机器学习进行数据分析,为混合云存储带来智能。
混合云环境通常包括组织自己的数据中心和多个公共云中的存储。历史上一直由It部门负责检查数据的使用方式、存储位置以及识别低效的地方。HPE的智能存储技术分析工作负载以了解底层需求,然后根据存储成本、性能、数据使用位置的远近和可用容量等指标将数据重新定位到最佳位置。智能存储产品还能实时适应变化的条件,并根据需要重新定位数据。
你希望完成什么?
希望利用机器学习能力进行存储的组织应该从决定他们希望获得什么开始。一旦确定了这些需求,他们就可以寻找直接满足这些需求的产品。例如,如果您的主要目标是优化性能,那么您可能希望为基于数据分析的产品寻找机器学习,这些产品能够以最小化延迟和避免IOPS浪费的方式自动安排数据。
根据确定的需求,组织可能不一定要购买存储硬件来利用机器学习。一个软件应用程序可以处理诸如自动容量规划之类的任务,而不需要新的存储硬件。